GPT-5 Prompting is Different - Here’s What Works
OpenAI released GPT-5 this week, and the prompting techniques that work best are fundamentally different from GPT-4o and o3. After spending several days converting workflows and experimenting with different approaches, the core difference is clear: GPT-4o and o3 excel at taking ambiguous prompts and iterating with you to reach a good result. GPT-5 does better with explicit, structured prompts upfront but delivers excellent results when you provide them.
The initial experience caught me off guard. Prompts that had worked consistently for months with both GPT-4o and o3 produced different outputs - not necessarily worse, just different in ways I didn’t expect. The buzz online reflects similar confusion, with many comparing it to earlier pre-reasoning model days when specific prompting techniques were essential. There’s truth to this - GPT-5 does require more structured approaches, but once you understand what it expects, the outputs are remarkably consistent and often exceed what GPT-4o or o3 could achieve.
Testing GPT-5 with Podcast Summarization
To understand GPT-5’s requirements, I tested it on a meta task: using GPT-5 to summarize a podcast episode about GPT-5 prompting techniques from The Daily AI Brief. The episode itself is excellent - genuinely actionable advice on how to use GPT-5 effectively, and worth the full listen if you want to dig deeper. I wanted to capture these techniques for myself and thought the exercise of using GPT-5 to extract GPT-5 prompting advice would be instructive.
I want to be clear - GPT-4o handles transcript summarization perfectly well, and I still use it for that. This was purely to see how GPT-5 would want this type of prompt structured.
My initial prompt was overly simple:
Your job is to analyze the following podcast transcript and identify all of the different prompting techniques mentioned. You should put each technique as a list item describe in one to two sentences what it is and add any additional bullet points around implementation details or things that are useful to know as you consider using the prompting technique.
This works okay with GPT-4o. But I wanted to see what GPT-5 preferred, so I used OpenAI’s prompting guide and prompt optimizer. This tool takes your existing prompt and rewrites it specifically for GPT-5. What makes it particularly valuable is that it shows you WHY it makes each change inline - teaching you the patterns GPT-5 expects while optimizing your specific prompt.
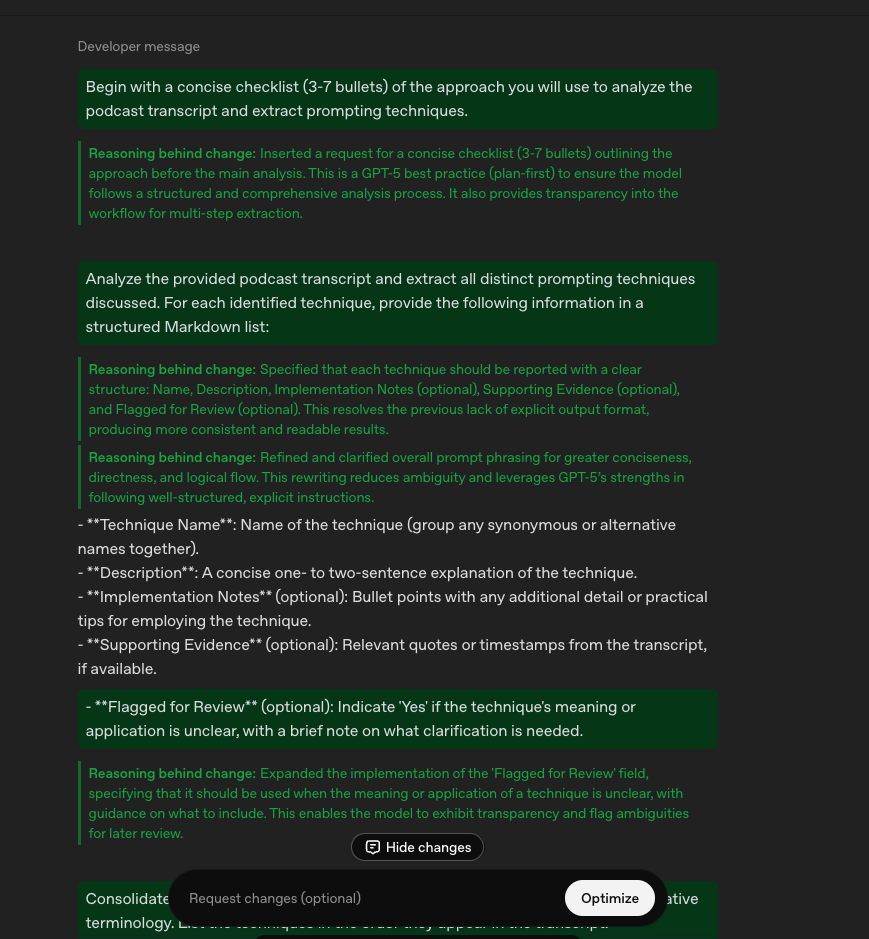
The optimized prompt it generated was significantly more structured:
Developer: Begin with a concise checklist (3-7 bullets) of the approach you will use to analyze the podcast transcript and extract prompting techniques.
Analyze the provided podcast transcript and extract all distinct prompting techniques discussed. For each identified technique, provide the following information in a structured Markdown list:
- Technique Name: Name of the technique (group any synonymous or alternative names together).
- Description: A concise one- to two-sentence explanation of the technique.
- Implementation Notes (optional): Bullet points with any additional detail or practical tips for employing the technique.
- Supporting Evidence (optional): Relevant quotes or timestamps from the transcript, if available.
- Flagged for Review (optional): Indicate ‘Yes’ if the technique’s meaning or application is unclear, with a brief note on what clarification is needed.
Consolidate duplicate or synonymous techniques into a single entry, noting alternative terminology. List the techniques in the order they appear in the transcript.
After compiling the list, quickly review and validate that all techniques are accurately extracted and grouped; if any ambiguities or uncertainties arise, briefly note them under ‘Flagged for Review.’
Output Format
Format your response as a Markdown list. Omit sub-bullets for Implementation Notes, Supporting Evidence, or Flagged for Review if not applicable to a given technique.
The optimized version included elements that helps steer the model to an unambiguous output: a pre-execution checklist requirement, explicit field definitions, instructions for handling duplicates and ambiguities, and precise formatting specifications.
GPT-5 Prompting Techniques from The Daily AI Brief
Running this optimized prompt produced a comprehensive extraction of every technique mentioned in the podcast. Here’s a sample of them:
- Technique Name: Escalate Thinking Depth (“Think harder,” “Think deeper,” “Ultrathink,” “Ultra-deep thinking mode”)
- Description: Add language that explicitly tells the model to think longer/deeper to improve reasoning quality.
- Implementation Notes: Append phrases like “think deeper” to prompts; optionally precede tasks with an “ultra-deep thinking” preamble that forces outlining, multi-angle checks, and verification.
- Technique Name: Explicit Planning Phases (Decompose → Clarify → Plan → Validate; “Mental To-Do List”)
- Description: Instruct the model to break the task into components, surface ambiguities, propose a plan, and validate understanding before answering.
- Implementation Notes: Use step headers like “Decompose,” “Ambiguities,” “Plan,” “Validate”; for longer tasks, track “Primary objective → Subtasks → Validation → Final review.”
- Technique Name: Be Extremely Explicit About Tone, Style, and Output Contract
- Description: Specify tone, formatting, and constraints precisely; GPT-5 is unusually sensitive to instruction style and will follow it tightly.
- Implementation Notes: State tone (“concise, neutral”), format (“bulleted, JSON, table”), and boundaries (“no hyperlinks,” “2 sentences per bullet”).
- Technique Name: Structured Prompt Specification
- Description: Enforce a clear schema for inputs/outputs; the benefit is structure and detail, not any specific format.
- Implementation Notes: Use a spec with sections: Definition, When (triggers), Output format/style, Sequence, Prohibitions, Handling unclear inputs.
- Technique Name: Require a Brief Reasoning Summary
- Description: Ask for a short explanation of how the answer was reached to improve performance on harder tasks.
- Implementation Notes: “Begin with a 3–7 bullet checklist of your approach” or “Add a brief ‘reasoning summary’ before the final answer.”
- Technique Name: Resolve Conflicting Instructions with Explicit Precedence Rules
- Description: Remove contradictions or tell the model which rule wins in specific scenarios to avoid wasted reasoning tokens.
- Implementation Notes: Add exception lines (e.g., “In emergencies, skip patient lookup and advise 911 immediately”).
- Technique Name: Iterative Self-Evaluation with Internal Rubric
- Description: Have the model craft an internal rubric and iterate until it hits top marks.
- Implementation Notes: Ask for a 5–7 category rubric, then require iteration until “top marks across all categories.”
- Technique Name: Metaprompting / Prompt Optimization
- Description: Ask GPT-5 what changes would help it follow a prompt better, or task it to write the best prompt for your goal.
- Implementation Notes: Provide the current prompt + known issues; ask for “minimal edits while keeping as much intact.”
- Technique Name: Control Reasoning Effort / Thinking Budget
- Description: Adjust the model’s thinking depth via API (
reasoning_effort: low/medium/high) or UI modes. - Implementation Notes: For heavier tasks, set higher reasoning effort; for low-latency tasks, lower it.
- Description: Adjust the model’s thinking depth via API (
Research Report Workflows: GPT-4o/o3 vs GPT-5
Beyond the podcast summarization experiment, I also converted several research report workflows to GPT-5 - actual work products, not just tests. These were prompts I’d been using successfully with GPT-4o / o3 for some time, but I wanted to see if applying the techniques above would make a difference.
It did. Using explicit thinking steps, precise format requirements, and edge case handling, I was able to exceed what I was getting from o3 in a few areas:
Citation consistency: When I specify how to cite the articles it searches and finds, GPT-5 actually follows through consistently. GPT-4o and o3 would cite sources when they felt like it. GPT-5 cites sources reliably when you tell it to.
Source quality filtering: GPT-5 seems more responsive to guidance about what types of sources to prioritize. Steering it toward the specific types of content and publications you want feels easier and more reliable than with o3.
Format stability: It’s easier to get GPT-5 to align with specific structures consistently. Even for longer reports or complex formatting requirements, the model maintains the structure you specify throughout the entire output. Surprisingly, it’s also quite good at building complex markdown tables with cited information within them - something I found fairly difficult to do with previous models.
Web search depth: Turning up web search to high via the API produced really nice results. GPT-5 was searching much more thoroughly - some prompts generated reports with upwards of 200 citations. The depth of research was noticeably better than what I’d seen before.
How GPT-5 is Different
It’s not that GPT-5 is fundamentally different from GPT-4o and o3 - all these models are capable of both conversational and structured approaches. The difference is where you invest your effort. With GPT-4o and o3, I’d typically start with a basic prompt and have a conversation to iterate toward what I wanted. With GPT-5, you get more value by spending time upfront crafting the right prompt and iterating on that single input rather than through multiple exchanges.
Both approaches work, but GPT-5 rewards the investment in prompt design more than previous models. If you’re willing to put in that upfront work, the consistency and precision you get back is notable.
This makes GPT-5 particularly well-suited for programmatic use. If you’re calling the API to get outputs, the design makes total sense - you specify exactly what you want and get consistent results. For conversational use cases like the ChatGPT application, I don’t have a strong view yet, but I’m using GPT-5 in that context too and haven’t switched back to the previous models.
Looking Forward
If you’re using ChatGPT, you’re already using GPT-5 - OpenAI switched the default model in the UI. Some people are switching back to GPT-4o because they’re frustrated with the changes. My view is that it’s better to invest time learning how to work with the leading-edge model, which is much more powerful once you understand how to use it.
The broader pattern here is interesting. AI tools are starting to split between “conversational” and “specification-based” approaches. GPT-5 leans toward the latter. When you tell it exactly what you want, it delivers exactly that. This makes it particularly good for programmatic use where consistency matters.
I think we’re going to see more tools make this choice. Some will optimize for exploration and flexibility. Others will optimize for precision and reliability. Understanding which tool fits which use case is becoming important.
The specific techniques I’ve covered here will change. OpenAI will update the prompt optimizer. New models will have different requirements. But the pattern of investing time to understand how each tool works best - that’s not going away.
If you’re hitting walls with consistency - citations that come and go, format drift in longer outputs, reports that vary in quality - try the prompt optimizer approach. See if the precision is worth the upfront investment in learning how GPT-5 works.